
A Decade in Data
A Data Scientist’s Perspective on Machine Learning, AI, and Green Tech Implications

For this installment of Green Tech Futures, I’ll be looking back on developments in data science over the last ten years, stretching back to my graduation from university in 2015, and considering how the domain of green tech has grown and changed along with them. The past decade has clearly seen big progress in some areas of data science, but from a statistical, scientific, and technological perspective, it has in many ways been surprising which innovations have had the most traction.
For me, one of the most interesting trends has been the rise of the term “data science” to describe a range of activities from data collection and cleaning to modeling and inference to data visualization and communicating insights. When I began digging into the particulars of statistical modeling while studying evolutionary biology, I considered myself a scientist with knowledge of data analysis, but it never would have occurred to me to look for a combined term to explain my skillset, much less to position it in the same context as others working in biomedical research, fraud detection, or linguistics. Instead, I considered statistical analysis to be a common tool used in each discipline for specific purposes.
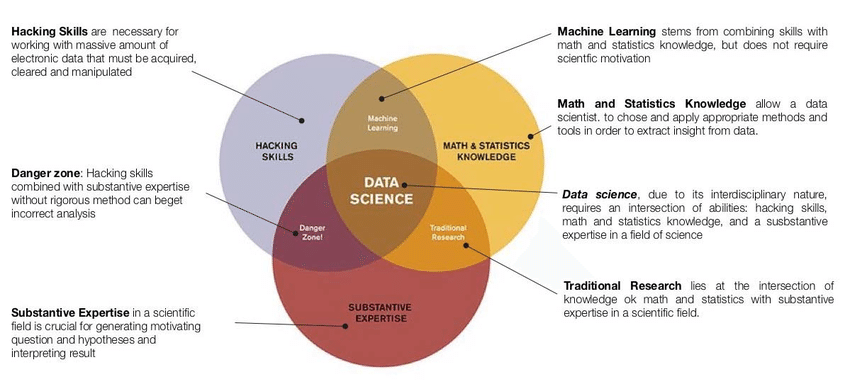
The data science perspective puts the lifecycle of data at the center and searches for the greatest drivers of value among data collection, analysis, and communication. Because of this focus on data above all else, advances from far-flung fields including cognitive science, cryptography, genomics, and medical imaging have contributed to state-of-the-art machine learning techniques and contemporary trends in AI like large language models. At the same time, data scientists must be careful to always stay grounded in the context of the data, keeping in mind its sources and intended uses.
For me, it’s become clear that the past ten years of progress in data science, machine learning, and AI represent a limited sample of the possibilities enabled by better hardware for data processing and more sophisticated algorithms for statistical inference. I also see a continued need for data scientists to understand the fundamental possibilities and limitations of analytical insight and to reflect on the provenance of data when deriving final insights from analyses.
2015-2017: Beginning in Biostatistics
Much of my perspective on data science and machine learning comes from my background in natural sciences and biostatistics, as opposed to data scientists who first approach the field from the direction of computer science. Ten years ago, I was in my senior year of undergrad, about to graduate with a major in biology and a minor in Earth science. Two of the most influential courses I took during that period would turn out to be a pair of biostatistics courses that focused on exploratory data analysis and statistical modeling using real-world data – with all the messiness that implied.

In my biostatistics classes and other courses I often made use of linear regression models, often with two to five coefficients fit to explain the variation in the dependent variable. A major advantage to this type of model is the relative ease of interpreting the relationship between the explanatory and dependent variables. Even when linear regression is expanded to generalized models, including logistic regression that predicts the likelihood of a binary outcome, or hierarchical models accounting for the effect of random variation in observations, the interpretation of coefficients is straightforward to determine from the model’s structure.
Linear regression is a type of machine learning model, a phrase which describes any mathematical model of a real system which derives its parameters from “learning” or “training” from real-world data. In the case of linear models, the explanatory variables are taken as “features” and the dependent variable becomes a “target,” and the coefficient of each explanatory variable is fit to minimize the error between predicted and observed values in the dependent variable. I encountered other machine learning models in the context of remote sensing. In my Earth science courses I explored supervised and unsupervised classification models for land cover from satellite images that captured up to seven distinct channels of light spectra reflected from the Earth’s surface. These models could be fit using more complex machine learning methods like random forests, which can lead to more robust models.
It is more practical to fit models like random forests when there is a large amount of data available to train the model during the learning phase. Remote sensing is a perfect example of a scenario in which a very large volume of data is collected, of which only a small portion of the data may be responsible for the variation of interest to researchers. Other advances around the same time came from similar fields like cancer imaging and genomic research, where datasets can have both a large number of features for training models and a large number of data entries to ensure a robust pattern of variation in the training data. In my biology studies, I even witnessed the development of custom image recognition models to identify individual animals like giraffes or whales from photographs, designed to aid in observational studies where the number of experienced researchers who can distinguish between subjects creates a bottleneck in data collection.
Around this time, big data techniques and sophisticated machine learning models were beginning to enter the public consciousness. A major watershed moment that I observed was in spring of 2015, when Google announced the development of the DeepDream software, which used neural networks to permute images with the psychedelic effect of emergent objects like animals, buildings, and eyes.

DeepDream served as an extremely effective demonstration of the potential of artificial neural network models, which work with large datasets like images (where each pixel can be considered to be a feature) by feeding the output of each feature into one or more hidden “layers,” nodes in which transformations and combinations with other features can be carried out with parameters trained through machine learning. These models are incredibly powerful, but they require large volumes of data with many potential features. DeepDream also indicated the growing importance of cloud computing infrastructure for data science breakthroughs, as its development was only possible as a result of Google’s previous investment in the cloud to power other software.
2018-2021: Rise of the Machine Learning
All of this excitement about the potential of big data created demand for a field of practice that would develop cutting-edge techniques to take advantage of large datasets and cloud computing power. By the time I graduated from my master’s program in 2018, I regularly saw data professionals describing themselves as “data scientists” and job descriptions calling for expertise in machine learning. I took a class focused on data science for biologists and learned a great deal about how to make data analysis replicable and consistent using tools like code notebooks and version control systems. But the most important scientific tools at my disposal remained the ability to generate and evaluate hypotheses and to communicate statistical findings clearly and effectively.
As I started my career as a data scientist working with agricultural commodities, I saw more and more examples of sophisticated data analysis that were summarized simply as “machine learning”. Often this meant complex models like regression trees or support vector machines, trained on large datasets from contexts like user behavior on websites and apps or transactions in financial markets. With the continuing growth of cloud computing power sold as a commodified service, it was becoming routine to speak of “big data” – machine learning models built from large datasets with hundreds or thousands of features and millions of data entries, which demanded distributed resources to train in a practical amount of time. Cloud architecture enabled both parts of this modeling paradigm, simplifying distributed data storage for large datasets and distributed processing for training complex models.
While financial traders, product marketers, and weather forecasters have access to large bodies of data from which to build complex machine learning models, natural systems like agriculture present a challenge for data scientists. Agricultural processes are integrative, transforming a season’s worth of sunlight, rain, humidity, wind, and soil nutrients into a single harvest which can be measured for yield and any other metrics of interest. The USDA has extensive data on crop production at the level of states and individual counties, stretching back to the early 20th century for most crop types; however, this is still only about 100 years of data. At the level of a single farm field, you would be lucky to find a record of harvests going back that far, considering how many owners and farm operators may have passed through the acreage.
The task for a data scientist working with data from nature is to work with inherently limited records, make thoughtful decisions about variables of interest based on knowledge of the natural system, and derive final output that is explicable, particularly to decision-makers and stakeholders. During this period, as machine learning went mainstream, I saw how many startups and established businesses scrambled to get an edge by building complex machine learning models, setting big data as its own imperative. In the cases where these models made a tangible impact, it was always because the data scientists building them understood the use cases for the stakeholders who would ultimately use the product of machine learning.
In other cases, big data machine learning models could produce apparent knowledge without providing insight or wisdom, especially “ensemble” models that were increasingly popular during this period, which combined the output of multiple models like random forests, support vector machines, and neural networks, all working with the same galaxy of features to predict a target variable. Typically in statistical modeling, using multiple models to predict the same outcome creates what is known as the multiple comparisons problem, where it is more likely that a false positive will exist among the models because the data just happen to fit the parameters. Ensemble models solve this issue using metamodeling techniques to find the best fitting combination of models, while attempting to avoid overfitting.
The issue with the ensemble modeling approach is that it can tend to turn into a soup of variables which all blend together. A model of models works well to blend different potential features that could be a proxy for an unmeasured variable affecting the dependent variable. For example, in modeling the productivity of crops like corn, an important measure is the accumulated “growing degree days,” a measure of daily temperature above a minimum temperature needed for plant growth. These growing degree days could be measured using different threshold temperatures, summed over different months, or the start of the accumulation period could vary with the pace of corn planting in a given year. One approach to building a machine learning model to predict corn yield from growing degree days could be to systematically build a series of models incorporating different specifications of the variable and different model structures, then compare the performance of the models against data that was not used to train them.
Using the ensemble modeling approach, a data scientist does not have to choose between these alternate variable codings, because unlike linear modeling, where including too many correlated variables can skew results, an ensemble model uses machine learning to predict the combinations of model design and explanatory variables that are most likely to fit the data and eliminate those which contribute little information. This has the benefit, or unintended consequence, of making model design much less important, and adding more data sources and potential features more important, to the process of data science. It is not possible to tease apart the individual influence of any variable on predicted outcomes, because the ensemble model is generated from a combination of models including all variables.
I saw this issue first-hand while working to predict fundamental supply and demand for commodity crops. At one point, a data scientist working in a different office came to my team with an unsolicited machine learning model that he felt could change the way my colleagues and I predicted crop production. We typically focused on researching crop yields at the level of states or agricultural districts, focusing on modeling production in the regions that produced the most concentrated volumes of a commodity. It was important to be able to answer questions from the trading floor about novel and unexpected scenarios quickly and walk through how changing weather and economic conditions could influence farmers’ planting, management, and harvesting decisions. To that end, I built many linear models to predict the fundamental components of crop production, use, and trade during this time, but as far as I know, the opaque big machine learning model that was presented to us really only appealed to a small group in the firm interested in replicating high-frequency trading strategies.
During the same period, there was another development that would eventually reshape the world of data science as we know it, or at least as the general public perceives it. In 2020, the AI research firm OpenAI released the GPT-3 language model, followed in 2021 by its offshoot, the DALL-E image generation model. These models took advantage of a revolutionary new framework called a “transformer” to efficiently generate output that had an uncannily strong resemblance to complex training data.
The transformer architecture trades increased time training a larger model for increased speed running the model to predict new data. A transformer is essentially a complex algorithm that is able to translate input, such as a user’s query or request, into a mathematical format that relates to its own internal representation of a massive body of training data. For GPT-3, the training data was text, and for DALL-E it was images annotated with captions. The resulting models seemed suitable for generating strange passages of text and surreal images that seemed to show the limits of the training data, but like DeepDream, it was not clear at the time if they would amount much else.
2022-2024: Data Science in the Age of “AI”
Although they may have seemed most suited to producing interesting novelties at first, transformer models turned out to be one of the most important developments in data science to date, building on previous advancements in big data machine learning like neural network models. These models crossed the threshold from neat but mostly useless to potentially world-changing quickly when OpenAI released the GPT-3.5 model in 2022. Even though GPT-3.5 was not versioned as a new major release, the impact was enormous. Large language models went from being able to produce an interesting paragraph that might shift its train of thought halfway, to producing text with more fluency than many humans. Uptake of GPT-3.5 increased when the ChatGPT interface was introduced at the end of 2022, allowing less technical users to access GPT-3.5 through a chat-like conversation.
For many, especially members of the general public, ChatGPT represented the beginning of the age of artificial intelligence. The term has been used to describe computers capable of human-like reasoning since the late 1950s1, but many initial advances in AI, such as programs that can play games like checkers and chess, mathematical theorem solvers, and expert systems capable of reasoning through scenarios, failed to make much of an impact beyond their own niche fields. This is partially a result of overinflated expectations: the term “artificial intelligence” seems to imply a human level of reasoning and inference, rather than highly sophisticated sub-human capabilities.
For this reason, large language models built with transformers, and particularly the familiar chat interface of ChatGPT, have revived expectations that human-like AI, properly termed “artificial general intelligence” (AGI), is within reach. The human capacity for language appears to be so basic to how we comprehend the world that researchers in linguistics debate whether our use of language determines the limits of our perception of reality. So the ability to have a dialog with GPT models, especially once OpenAI released their next-generation GPT-4 model in 2023, immediately caught on and expanded uptake of large language models.
One interesting effect of the success of ChatGPT and other integrated large language models like the Copilot code editor is how they seem to have sucked the air out of the room for previous advances in machine learning. As of 2025, the average person who is asked about AI would probably describe using ChatGPT to draft emails and essays or to work through a business plan, rather than considering the computer vision systems, recommendation engines, and prediction models enabled by previous advances in machine learning. In fact, it is more common to see machine learning bundled into “AI/ML” and to describe using AI to train a model, because this creates a sense of association between the astonishing results of transformer models and the impressive output of traditional machine learning.
Another outcome of the proliferation of large language models has been to introduce the kinds of problems that a data scientist deals with to new contexts. GPT-3’s solid results, while not as convincing as the output of GPT-4 and more recent models, came about because the model was trained on a huge volume of data sourced from global literature and websites across the internet. Improving these models has generally relied on both improvements to the model architecture and ingesting new data.
While training a transformer model on a gigantic body of assembled texts is enough to produce grammatically correct content, formatted appropriately and written in any required tone or translated into another language, these models are not capable of insight into what they produce. ChatGPT is known to “hallucinate,” confidently stating falsehoods, because the model is trained to produce grammatical text and not necessarily to be correct. Attempting to address this by adding more text to the training data is difficult; acquiring new source texts has become progressively more difficult as a greater fraction of available data is included in training, authors and publishers have become more protective of their copyright after seeing the value of the models produced using their data, and more AI-generated content has been published online, which can reduce the quality of the training data.

To resolve this, researchers are trying several approaches. One possibility is the use of “retrieval-augmented generation,” where a language model is used to search a database of known knowledge and return valid results. Another possibility is to take transformer models in a different direction than language. So-called “foundation” models rely on the transformer architecture to learn the fundamentals of a system like molecular reactions, weather and climate data, or social networks from the ground up, without relying on knowledge encoded in language.
Both of these approaches face a similar issue, which is the need to gather and parse this novel data so that the database can be organized for retrieval or so a foundation model can be trained. This means that like many complex machine learning models, these applications of transformers are best suited to settings where there is a rich body of data with many potential features and data entries to train a model with.
So in this way, I have seen developments in data science come full circle to the same issues I faced a decade ago, when I started from a statistical modeling approach. Contemporary AI models take large amounts of time and energy to train, require large amounts of well-defined training data, and still struggle to produce explicable predictions that can be extended to novel situations.
For the discipline of data science, I increasingly see how the way forward is to return to considering the overlapping problems of data collection, analysis, and communication. Machine learning and AI have shown how far data analysis can be pushed to generate insights and predictions from large, complex datasets, but in many situations, the bigger challenges are collecting data and communicating expected outcomes.
In contexts like endangered species conservation and regenerative agriculture, practitioners are often trying to do something that has never been done before, and with limited resources. Therefore, it is unlikely that an existing pre-trained model like GPT-4 will be able to provide insights that are useful, and it will be necessary to build something new. Because the available data in these fields are generally significantly less rich than the big data needed to train advanced machine learning models like neural networks, data scientists must rely on simpler models like linear regression. Ultimately, impact depends on how the end users of data understand the insights and recommendations derived from the output of models, not only whether data scientists can reduce variance between predicted outcomes and reality.

There are some areas where developments in machine learning and AI can help natural scientists understand the biology and geochemistry underlying issues like climate change and biodiversity loss. In particular, big data techniques are adept at sorting through large volumes of data gathered by automated sensors, such as satellite imagery, weather stations, audio monitoring, or camera traps. In these cases, data scientists can use machine learning to derive useful features for modeling. But most of the time, the real edge to be gained is in having a better understanding of the most salient features and most relevant outcome variables to train models on, and that requires a deeper understanding of the system being studied.
With a decade of growth as a data scientist, first as a graduate student and later as a professional working in the agribusiness industry, I have seen all of these trends arrive on the scene, only to be replaced with newer trendy techniques. But progress with new machine learning and AI models does not mean that older methods no longer work, and I find that the projects that excite me the most these days use relatively simple models to produce comprehensible explanations of predictions. Usually, the interesting and novel piece of these models is the data collection process behind them, not the multitude of parallel processors and millions of mathematical operations required for training in a big data context.
Some day, sooner than we think, someone will invent a new type of machine learning architecture that makes transformers look as relatively unsophisticated as decision trees. When that happens, I fully expect them to claim that the new model can solve all types of difficult problems, just like what happened with the advent of transformers. But to solve any real issues, especially in natural systems, will take more than just computing power and time – it requires understanding the fundamentals of the system, which variables are of interest and which are spurious, and how to communicate outcomes to stakeholders and to the general public.
For the next decade in data, we need to lower the barriers to understanding machine learning models so that more people can work on developing new ones, but also so that the public is well-informed about how these models work, and don’t work. Building opaque models that predict outcomes with very little error is only a reasonable approach when you do not have to explain the results of your work to any stakeholders. Instead, I hope that near-future advances in machine learning for natural sciences focus more on building interpretable models.
The term “artificial intelligence” was coined at a workshop at my alma mater, Dartmouth College, in 1956. Before this, many of the concepts associated with AI were studied in fields such as cybernetics, control theory, and information processing.
I always look forward to reading these reports!